Meta-тег robots и canonical: как избежать конфликтов и дублей в индексе?
— по оценке 15 пользователей
25 февраля, 08:18
Meta-тег robots и атрибут canonical часто настраивают одновременно, но сочетают неправильно. В итоге получают дубли в индексе, перерасход краулингового бюджета, настабильную каноникализацию.
Зачем нужны директивы meta-тега robots, если уже есть canonical и наоборот – нужно ли указать каноническую версию документа при уже настроенном запрете индексации?
Очевидно, что есть разница в выполняемых этими инструментами задачах. Meta-тег robots управляет индексацией страницы роботом и возможностью его путешествия по ссылкам на ней (читай: решает, что попадет в индекс). Атрибут canonical же в свою очередь подсказывает поисковику основную версию документа среди дублей.
Для робота директивы в meta-теге, как правило, исполняются, если страница доступна к обходу, а в canonical – просто рекомендация.
Как уже было сказано выше, сочетание директив управляет индексацией и обходом ссылок. Index дает разрешение на индексацию, а noindex, соответственно, запрещает индексацию документа.
Как он работает для уже проиндексированных страниц? Очень просто – при смене директивы на запрещающую, после того, как бот обойдет страницу и увидит noindex, URL начнет удаляться из индекса (не в моменте, а с некоторой задержкой).
Теперь рассмотрим сочетание follow и nofollow, когда они имеют смысл. Follow разрешает обход по ссылкам даже для страницы с директивой noindex. Это означает, что робот не будет индексировать документ, но будет переходить по ссылкам, находить новые и быстрее переобходить связанные URL.
Для большинства фильтровых страниц с товарами правильное решение:
Исключением, пожалуй, являются «мусорные» результаты фильтрации, которые плодят еще больше таких же бесполезных результатов – своеобразный бесконечный фильтр. В этом случае верной будет директива:
Как видим, nofollow управляет краулингом и применяется там, где расход краулингового бюджета рискует быть бесконечным.
Какие же есть риски использования директивы nofollow? Например, если на страницах фильтраций есть ссылки на товары, которых нет ни в карте сайта, ни на других листингах, то поисковый робот может никогда не добраться до них. Таким образом, при слабой структуре сайта или отсутствии уверенности в ней, лучше директиву nofollow не использовать.
Если на сайте по той или иной причине есть ряд дублей, то с помощью canonical можно указать роботу, какой документ считать основным (каноническим). С помощью этого атрибута можно «схлопывать» дубликаты в рамках сайта, но он является лишь рекомендательным. То есть это скорее подсказка, чем строгое указание.
Пример типовой фильтровой страницы интернет-магазина:

У нее есть:
Мы с одной стороны говорим, что это документ «мусорный», а с другой - указываем, что это основной URL. Более того, еще и запрещаем ходить по ссылкам.
Это не столько конфликт, сколько бессмысленная связка: страница помечена как неиндексируемая, поэтому canonical не решает задачу выбора канонической версии.
Решением видится заменить директивы meta-тега robots на noindex, follow. А в качестве канонической указать раздел (без фильтра), которому они принадлежат (если результаты фильтрации не являются самостоятельными страницами с ЧПУ).
Атрибут canonical помогает нормализовать индекс, но для краулинга важно также не генерировать параметрические URL и исключить их из sitemap.xml.
Что нам это даст? «Схлопнем» сотни тысяч комбинаций фильтра и дадим роботу новые пути обхода карточек товаров.
Встречаются примеры обратных конфликтов. Для пагинаций может быть настроено так:
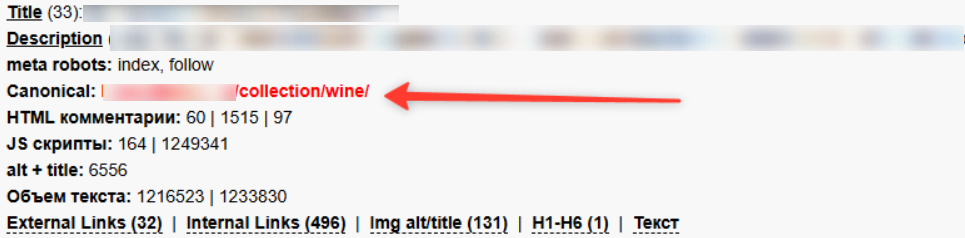
Мы разрешаем роботу индексировать документ (index, follow), а далее ставим canonical на первую страницу и говорим, что это дубли и основной считаем другую. Если сайт — крупный интернет-магазин, бот будет активно обходить пагинацию, но canonical на первую сообщает, что эти страницы не самостоятельны, что дает перерасход краулингового бюджета без пользы.
Как поступить правильно? Если товары доступны через категории, карты сайта, и у нас нет цели индексировать пагинацию, то:
Если же пагинация — это единственный путь к части товаров, то придется оставлять:
Это довольно частый пример смешанной команды, когда мы просим не индексировать один документ, но при этом говорим, что основным из списка таких же дубликатов надо считать другой.
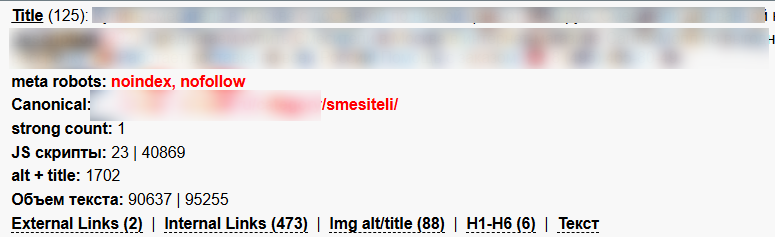
Какие цели преследуют сочетанием таких директив? Скорее всего, хотят убрать исходную страницу из индекса, но склеить ее с другой, считают canonical аналогом 301-редиректа (якобы он способен перенести вес) или борются с результатами фильтрации, ставя canonical на категорию.
Такое сочетание, как правило, некорректно, так как представляет собой противоречивые сигналы. Поисковая система может удалить из индекса исходную страницу, но не принять рекомендацию canonical, особенно, если контент отличается.
Кроме того, указание канонической страницы может быть не просто проигнорировано, но робот выберет такой URL на свое усмотрение или будет «колебаться» при каждом обходе.
В редких случаях связка noindex + canonical на другой документ может использоваться как компромисс: например, когда существует технический дубль, а настроить 301-редирект или нормализацию URL нельзя из-за ограничений платформы. В общем случае связка noindex + canonical на другую страницу смешивает задачи и может дать непредсказуемый результат.
Важно помнить, что robots.txt управляет обходом, а не индексацией и вот здесь шутки совсем плохи. Если закрыть в нем «мусорные» страницы и добавить на них meta-тег robots и canonical, то вне зависимости от правильности или неправильности их указания ничего не поменяется – робот туда даже не придет, и соответственно, никогда не увидит ни рекомендаций, ни директив. А «мусор» может долго оставаться в индексе и фигурировать в отчетах со статусом «Заблокировано в файле robots.txt». Вряд ли нам это нужно?


Комментариев пока что нет
Входим в число лучших компаний России в сферах интернет-рекламы и разработки сайтов по результатам самых авторитетных рейтингов







В этой статье объясняется, что такое API, как устроен принцип его работы и где он применяется. Материал будет полезен разработчикам, предпринимател...




Нужна помощь с сайтом? Заполните форму, и наши менеджеры проконсультируют вас уже сегодня!


Уникальный тариф «Оборот», где доход агентства больше не зависит от визитов и позиций вашего сайта, а привязан исключительно к росту оборота вашей компании.
Тариф, который хотели сделать многие, но реализовали только мы.
