5 способов, как посмотреть сайт «глазами» Googlebot
— по оценке 29 пользователей
20 августа, 16:34

4443
3
9
Возможности Google в области искусственного интеллекта стремительно развиваются: обзоры с использованием ИИ стали появляться по все большему числу поисковых запросов. Несмотря на постоянные изменения формата органической выдачи, основы SEO остаются актуальными.
Если вы хотите, чтобы ваш сайт индексировался, высоко ранжировался в результатах поиска, а также фигурировал в сгенерированных ответах искусственного интеллекта, важно убедиться, что Googlebot (как и другие поисковые системы) имеют доступ не только к страницам сайта, но и к их контенту.
Если робот Googlebot не может получить доступ к контенту страницы, он не может быть процитирован, а значит страница не займет ожидаемые позиции и не попадет в поле зрения ИИ.
Такая проблема достаточно распространенная и может встречаться практически на любом типе сайтов. Например, у интернет-магазина могут быть скрыты превью карточек товаров.
В таких случаях поисковым роботам сложнее обнаружить ссылки на детальные страницы карточек товаров, чтобы просканировать их, проиндексировать или цитировать, особенно если на них нет ссылок с других страниц сайта или они не включены в файл sitemap.xml (а должны быть!).
Если вы подозреваете, что поисковик не может получить доступ к какой-либо части контента вашего документа, предлагаем пять способов, которые помогут вам увидеть ваш сайт так, как его видит Googlebot. При необходимости можете использовать несколько из этих методов одновременно, чтобы убедиться, что получаются идентичные результаты везде.


Давайте приступим!
Google Search Console — это бесплатный инструмент, в котором должны быть добавлены все сайты у SEO-специалиста. Помимо просмотра данных об эффективности органического поиска, вы также можете проверять отдельные URL-адреса на наличие проблем с индексацией, запросив информацию из индекса Google или запустив тестирование в реальном времени.
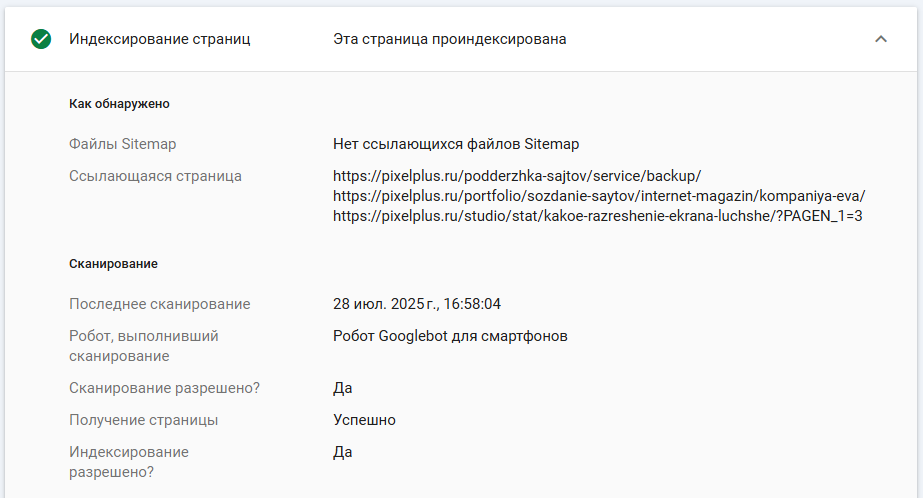
Запрос информации из индекса Google позволит вам узнать, был ли URL-адрес проиндексирован или нет во время сканирования. Это полезно для определения, не индексируется ли URL-адрес из-за тега noindex, канонического адреса или документ не может быть просканирован из-за блокировки в файле robots.txt. Вы также можете узнать, откуда робот Googlebot обнаружил ваш URL-адрес (из карты сайта, с внешнего сайта и т. д.).
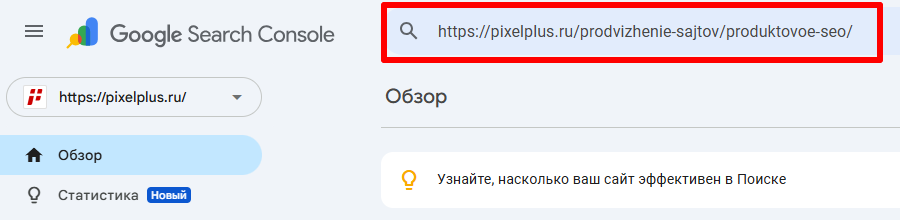
Но если вы хотите увидеть, как Google видит вашу страницу сейчас, вам необходимо запустить тестирование в реальном времени. Для этого:
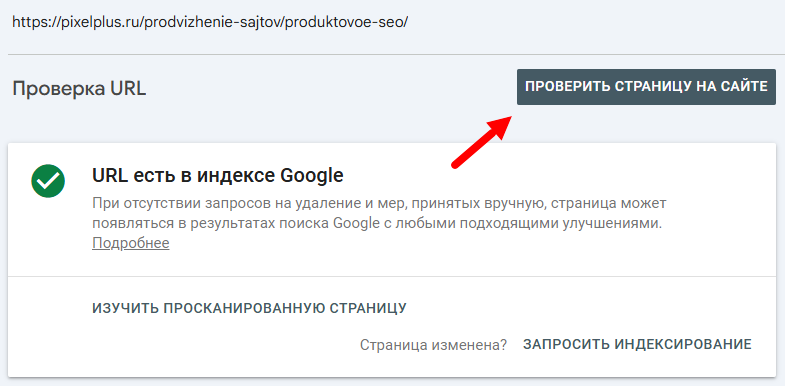
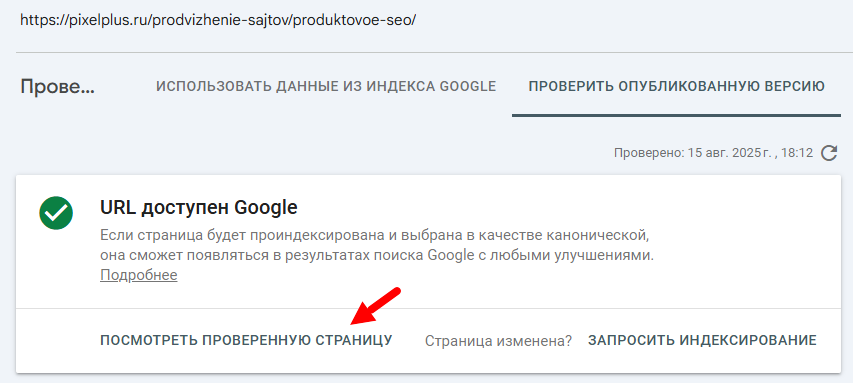
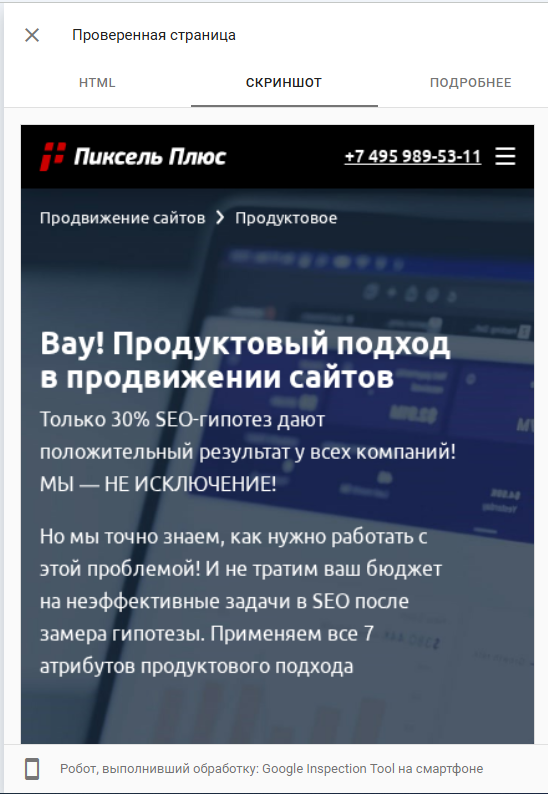
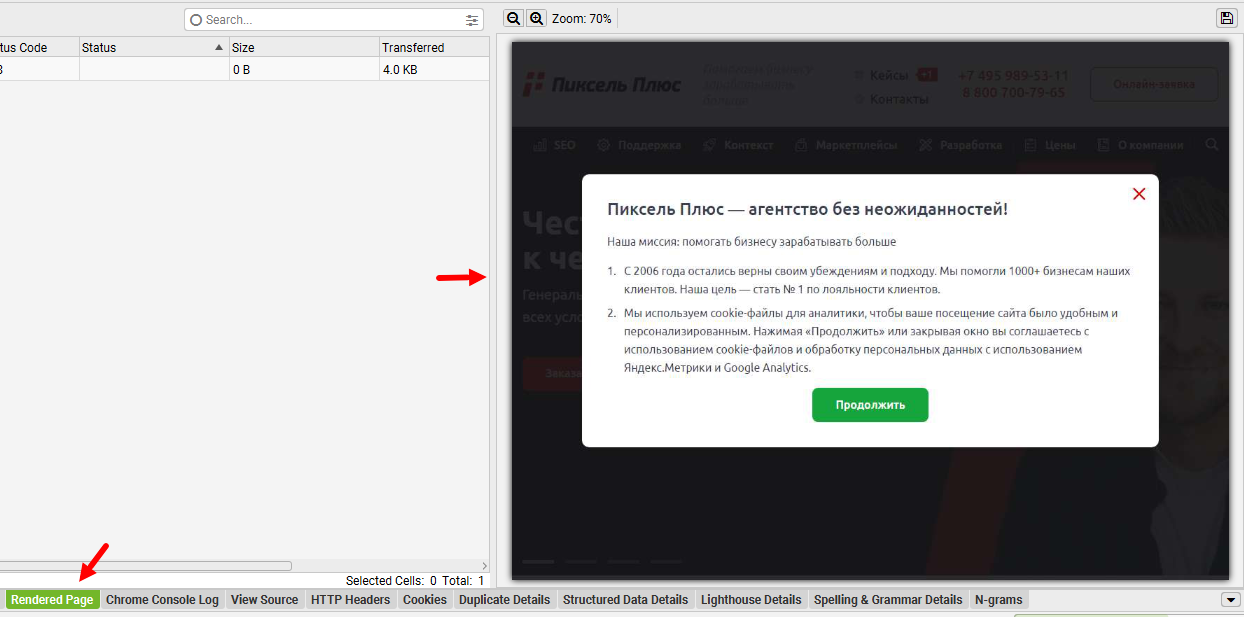
Если на скриншоте отсутствуют элементы вашей страницы, это может быть связано с блокировкой ресурсов для Googlebot. Вы можете узнать, какие ресурсы были заблокированы, нажав на вкладку «ПОДРОБНЕЕ» рядом с пунктом «СКРИНШОТ».
Преимущества:
Недостатки:
Программа Screaming Frog решает множество различных задач, и она является неотъемлемым инструментов любого SEO-специалиста.
Если вы не пользовались программой, то, по сути, от вас требуется просто ввести URL-адрес сайта и он просканирует ссылки по этому URL-адресу, чтобы найти связанные страницы и внешние ресурсы.
Screaming Frog позволяет обнаружить проблемы SEO, которые могут влиять на индексацию и ранжирование сайта, экспортировать URL-адреса, найти неработающие ссылки, дубли тегов и т. д.
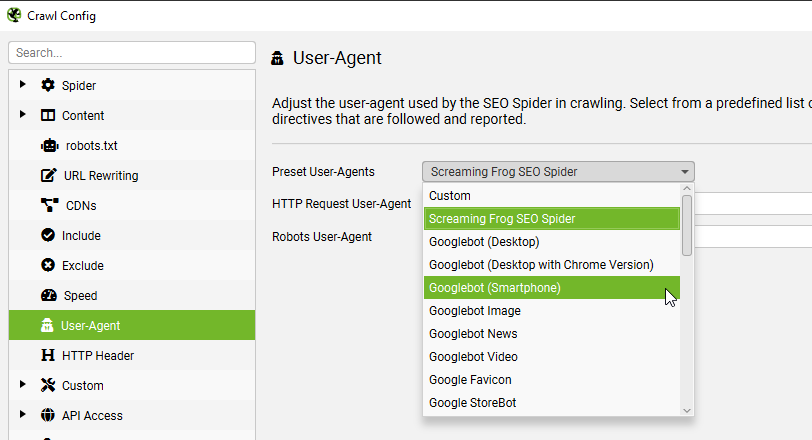
По умолчанию инструмент использует User-agent: Screaming Frog SEO Spider, но его можно изменить на агенты Googlebot, Bingbot, Yahoo-Slurp, DuckDuckBot и других.
Если вы хотите проверить, есть ли у вас проблемы с доступом Googlebot к контенту страниц, вы можете изменить User-agent, перейдя в раздел «Configuration» > «User-Agent» > и выбрать нужный в раскрывающемся списке.
Поскольку Google использует индексацию, ориентированную на мобильные устройства, рекомендуем начать с Googlebot Smartphone.
Далее вам просто нужно ввести URL-адрес или домен сайта, с которого вы хотите начать, и позволить Screaming Frog просканировать его до 100%.
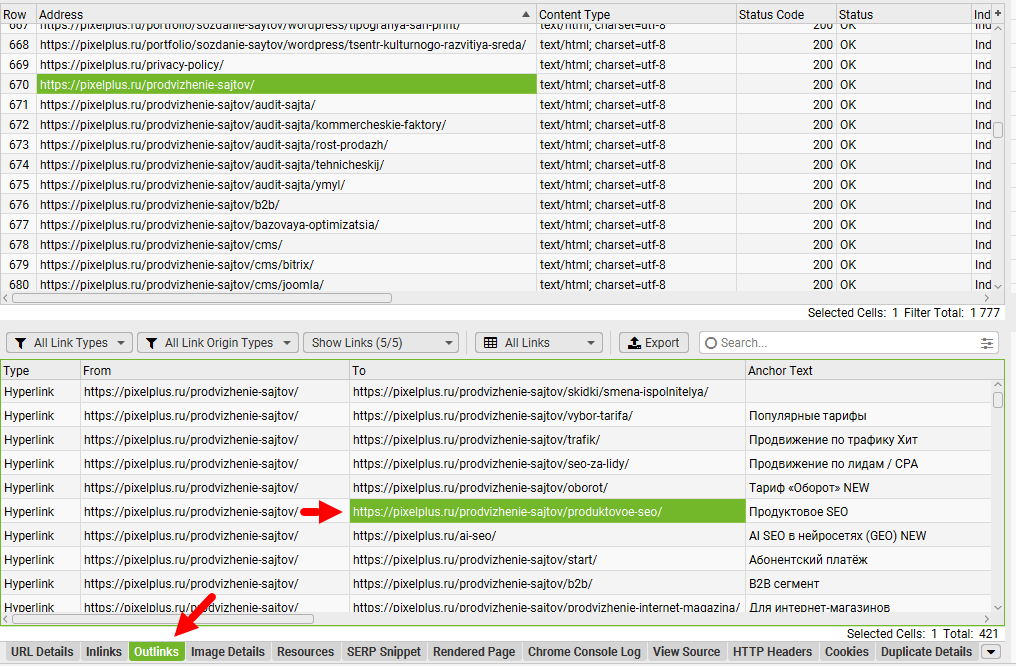
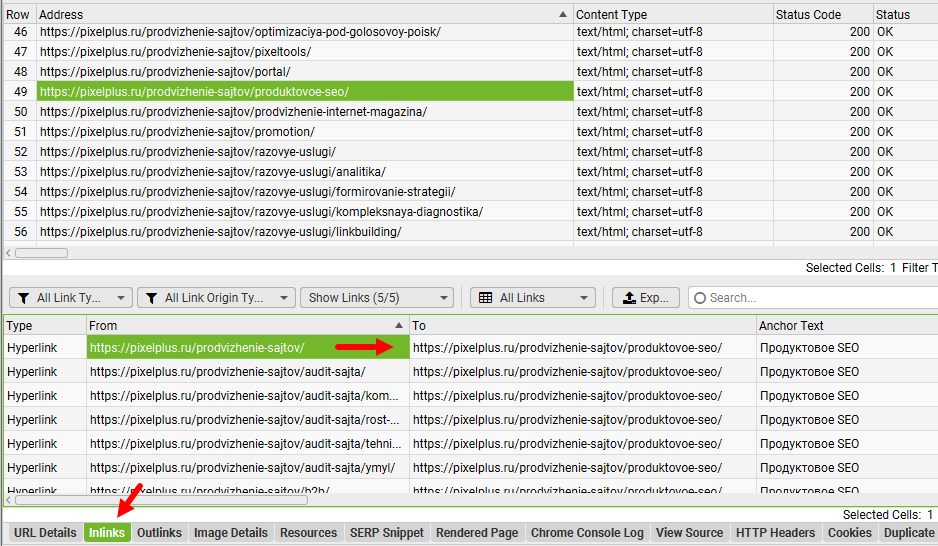
Если, например, вы считаете, что робот Googlebot не может получить доступ к ссылкам на отдельные URL раздела, сначала найдите основную страницу в результатах сканирования Screaming Frog и выберите ее.
Затем откройте вкладку «Outlinks» в нижней части инструмента, чтобы увидеть, какие ссылки Screaming Frog нашёл на этой странице. Если он не получает URL-адреса отдельных записей, это может быть признаком того, что робот Googlebot не может получить доступ к ссылкам на документы с основной страницы.
Вы также можете немного изменить процесс, выбрав URL-адрес отдельной страницы, а затем открыть вкладку «Inlinks», чтобы увидеть страницы, на которых программа нашла ссылку на эту запись. Если Screaming Frog не нашел публикацию как входящую ссылку из блога, это может быть признаком того, что Googlebot не может получить доступ к ссылкам на отдельные записи в вашем блоге.
Преимущества:
Недостатки:
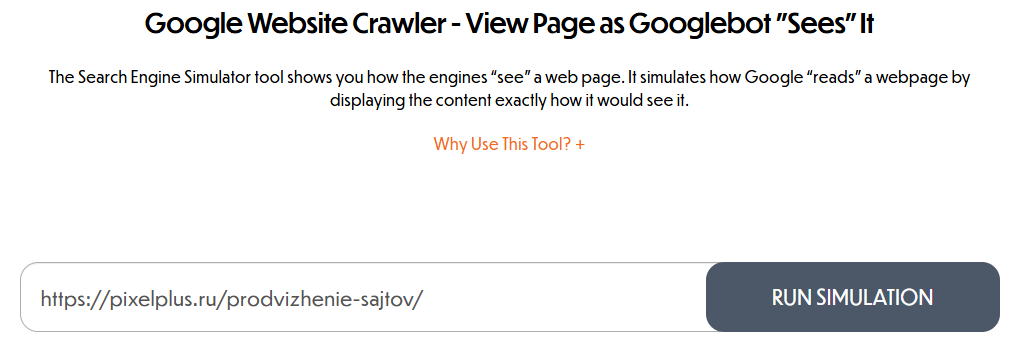
Инструмент Google Website Crawler прост в использовании — просто введите нужный URL-адрес в строку поиска, и инструмент выдаст все ссылки, доступные Googlebot.
Преимущества:

Недостатки:
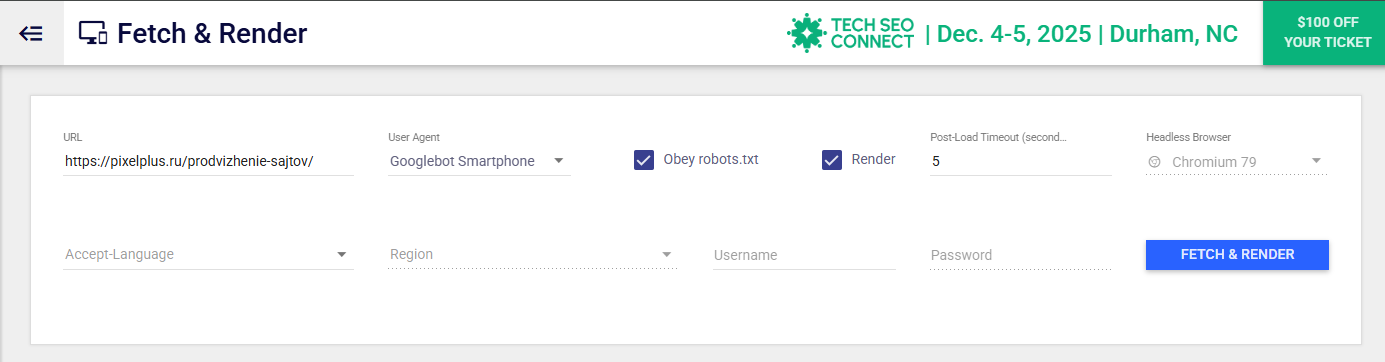
Как и Googlebot Crawler Simulator, инструмент Fetch & Render такой же простой в использовании — необходимо ввести URL-адрес, выбрать User-Agent, настроить параметры, а затем запустить тест.
Преимущества:
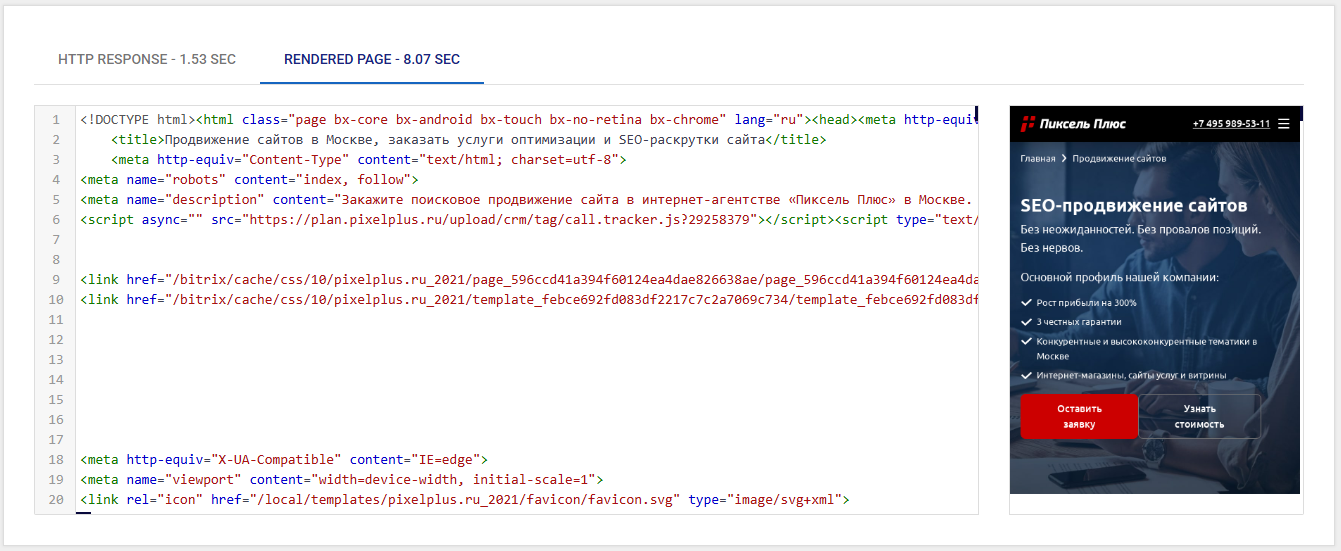
Недостатки:
Сервис проверки расширенных результатов идентичен пункту №1 и его также можно использовать для постраничного анализа сайта. Для этого достаточно ввести необходимый URL-адрес страницы.
В результате проверки вы получите информацию о микроразметке страницы, а также сможете увидеть скриншот:
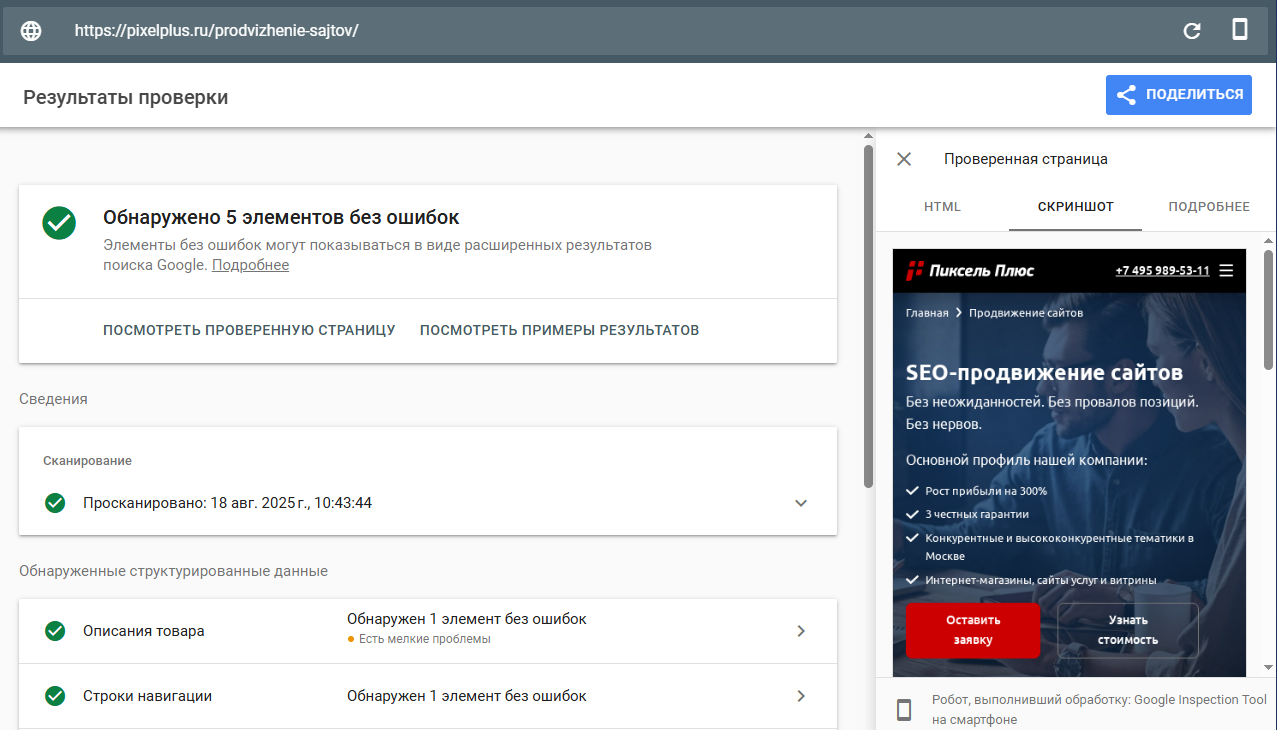
Преимущества:
Недостатки:
Если вы попробовали все методы и выяснили, что контент страницы недоступен для поисковых роботов, самое время разобраться, в чём дело.
Выделим две наиболее распространенные проблемы:
Это может показаться очевидным, но стоит перепроверить. Если вы создали файл robots.txt, проверьте его, чтобы убедиться, что вы случайно не блокируете сканирование страниц.
Кроме того, отдельные страницы потенциально могут быть закрыты от индексации — либо с помощью вручную добавленного мета-тега <meta name="robots">, либо за счет настроек в CMS (плагин Yoast в WordPress, настройки индексации в Tilda и т.д.).
Наконец, если ваш сайт защищен брандмауэром или системой безопасности, например Cloudflare, убедитесь, что роботам поисковиков разрешен доступ на ваш сайт для сканирования и индексации страниц.
В связи с популярностью систем управления контентом и платформ электронной коммерции, клиентская обработка стала серьезной проблемой для SEO. Это, в основном, проблема разработки программного обеспечения, когда программисты используют ту или иную технологию, не понимая, как она влияет на работу поисковых роботов и индексацию сайта.
Когда посетитель или поисковый робот заходит на ваш сайт, его браузер отправляет запрос на ваш сервер. Затем сервер визуализирует полный HTML-код вашей страницы, включая динамический контент, и возвращает его посетителю в виде отображения в его браузере. Это называется рендерингом на стороне сервера (SSR: Server Side Rendering).
При клиентском рендеринге (CSR: Client Side Rendering) когда посетитель или поисковый робот отправляет запрос к вашему серверу, сервер отвечает практически пустым HTML-файлом, содержащим ссылки на файлы JavaScript с данными и инструкциями о том, как браузер посетителя должен отображать страницу. Это часто включает загрузку и отображение частей страницы, с которыми пользователь уже взаимодействовал, а не при первоначальной загрузке.
Проблема CSR заключается в том, что, хотя большинство из поисковиков могут выполнять JavaScript, они спроектированы для очень быстрого перехода между страницами. Когда робот получает от сервера практически пустой ответ, он практически не находит контента для индексации и может продолжить работу до того, как связанные данные JavaScript будут загружены.
Кроме того, если некоторые элементы страницы, например, главное навигационное меню, заполняются только по клику или наведению курсора, содержимое внутри меню не будет индексироваться или сканироваться, поскольку оно будет невидимо для робота.
Несмотря на то, что существуют решения для разработки клиентских сайтов, корректно отображаемых с точки зрения SEO, разработчики зачастую не учитывают это и не всегда понимают критичность влияния своих решений на сканирование страниц сайта.
Некоторые современные фреймворки, такие как Next.js или Nuxt, предлагают различные режимы рендеринга, и их необходимо тщательно продумать. Разработчики также должны быть более внимательны к SEO-требованиям при работе с сайтом.
Если вы подозреваете, что на вашем сайте есть проблемы с полнотой индексации контента, но не знаете, как их выявить или устранить, можете обратиться к нашим специалистам по SEO и разработке. Мы поможем вам разобраться!
Комментариев пока что нет
Входим в число лучших компаний России в сферах интернет-рекламы и разработки сайтов по результатам самых авторитетных рейтингов

















В этой статье объясняется, что такое API, как устроен принцип его работы и где он применяется. Материал будет полезен разработчикам, предпринимател...





Нужна помощь с сайтом? Заполните форму, и наши менеджеры проконсультируют вас уже сегодня!


Уникальный тариф «Оборот», где доход агентства больше не зависит от визитов и позиций вашего сайта, а привязан исключительно к росту оборота вашей компании.
Тариф, который хотели сделать многие, но реализовали только мы.