Каждый месяц сотни сайтов теряют позиции в поиске из-за неправильных настроек для роботов поисковых систем. Одна неправильная строка в robots.txt или некорректно настроенный meta-тег robots может привести к исчезновению целых разделов из выдачи или, наоборот, к индексации «мусора» и, что еще критичнее, конфиденциальных данных.
Предлагаем разобраться и закрыть вопрос: как правильно закрывать страницы от индексации, какой вариант лучше использовать и почему?
Начнем с небольшого теоретического блока, он тоже важен!
Что такое robots.txt?
Robots.txt — это текстовый файл, который в 99% случаях лежит в корневой папке сайта, содержащий список инструкций для поисковых роботов о том, какие разделы сайта следует или не следует сканировать.
Файл robots.txt — для управления сканированием.
Что такое meta-тег robots?
Meta-тег robots — это HTML-тег, размещаемый в коде страницы (внутри тега <head>), который дает точные указания поисковым системам о том, индексировать ли конкретную страницу и учитывать ли в формуле PageRank исходящие ссылки на ней.
Meta-тег robots — для управления индексацией.
Почему нельзя просто открыть весь сайт для поисковиков?
Представьте, что ваш сайт — это музей. Если позволить посетителям свободно ходить по всем помещениям, включая служебные комнаты, подсобки и реставрационные мастерские, главные экспонаты останутся без внимания. Точно так же и с поисковыми роботами: без четких указаний они будут тратить ограниченное время на изучение технических разделов вместо индексации важных для бизнеса страниц.
Вспоминаем понятие «краулинговый бюджет»
Простыми словами — это количество страниц вашего сайта, которое поисковая система может обойти за определенный промежуток времени. Если поисковый робот потратит выделенный бюджет на архивы, «мусор» и технические дубли, ключевые продвигаемые страницы страницы могут просканироваться не сразу (не попасть в индекс, не обновятся корректировки оптимизации).
Какие страницы опасно показывать поисковикам?
Дубли страниц — идентичные версии одной страницы с разными URL-адресами.
Личные кабинеты — страницы авторизации, истории заказов.
Страницы-заглушки — «скоро появится», «в разработке».
Корзина покупок и страницы оформления заказа.
Риски неправильных настроек?
Потеря трафика — когда робот индексирует большое количество технических страниц вместо основных, коммерческих.
Индексация мусора — появление в поиске неуникального или служебного контента.
Утечка данных — случайное попадание в поиск служебной информации.
Снижение позиций — из-за проблем с краулинговым бюджетом и большим количество дублей продвигаемых страниц.
Грамотное управление роботами поисковиков — это не ограничение, а оптимизация их работы. Как опытный администратор музея направляет посетителей по самым ценным экспозициям, так и веб-мастер должен направлять роботов к самым важным страницам сайта.
Файл robots.txt: шлагбаум для поисковых роботов
Представьте, что ваш сайт — это бизнес-центр с охраной на входе. Файл robots.txt — это именно тот охранник, который дает роботам-посетителям первоначальные указания: «Какие коридоры можно обследовать, а какие — обойти стороной». Это текстовый документ, к которому роботы обращаются в первую очередь, еще до начала изучения каких-либо страниц.
Рассмотрим основные команды Robots.txt
Команда
Простой смысл
Когда применять
Пример
User-agent
«Это указание для...»
Когда нужно дать команду конкретному поисковому роботу
User-agent: Yandex (только для Яндекса) User-agent: * (для всех роботов)
Disallow
«Не заходи сюда»
Для закрытия целых разделов, папок или типов файлов
Disallow: /admin/ Disallow: /tmp/
Allow
«Но сюда можно»
Для создания исключений внутри запрещенной зоны
Disallow: /admin/ Allow: /admin/public/
Sitemap
«Вот карта сайта»
Чтобы помочь роботу быстрее найти все важные страницы
Sitemap: https://site.ru/sitemap_new.xml
Сильные и слабые стороны robots.txt
✅ Плюсы:
Экономит ресурсы робота — не тратит время на сканирование технических разделов.
Управляет целыми разделами — одной строкой можно закрыть всю папку.
Простота настройки — достаточно создать один файл в корне сайта.
❌ Минусы:
Это просьба, а не приказ — тот же Google спокойно может проигнорировать запреты.
Не защищает файлы — запрет в robots.txt не является защитой от прямого доступа.
Важное уточнение: robots.txt — это указание для сканирования, а не для индексации. Директива в файле может запретить роботу загружать содержимое страницы, но не может гарантировать, что эта страница не попадет в поисковый индекс, если на нее ведут ссылки внутри сайта и с других ресурсов.
Мета-тег robots: инструкция для каждого кабинета
Если файл robots.txt — это охранник на входе в бизнес-центр, то мета-тег robots — это индивидуальная табличка на двери каждого конкретного кабинета. Этот HTML-код размещается в коде страницы (внутри тега <head>) и содержит прямые указания для поисковых роботов, которые уже зашли внутрь.
Комбинации <meta name=”robots”> и их смысл:
Команда
Что означает
Где использовать
index, follow
«Индексируй эту страницу и переходи по ссылкам на ней»
Обычные страницы, которые должны быть в поиске (стандартное поведение)
noindex, follow
«Не показывай в поиске, но ссылки с нее учитывай»
Страницы-воронки, формы заявок, контент для партнёров
index, nofollow
«Показывай в поиске, но по ссылкам не переходи»
Страницы с пользовательским контентом, комментариями
noindex, nofollow
«Полностью игнорируй эту страницу»
Служебные страницы, черновики, временные акции
Когда meta-тег robots незаменим?
✅ Плюсы:
Точечный контроль — можно управлять индексацией каждой страницы индивидуально.
Абсолютная власть над индексацией — параметр [noindex] гарантированно исключает страницу из поиска.
Надежность — это прямое указание, а не просьба, которую можно проигнорировать.
❌ Минусы:
Робот тратит ресурсы на загрузку — чтобы прочитать тег, робот должен загрузить страницу.
Сложность массового управления — для изменения настроек множества страниц требуются технические решения.
Не экономит краулинговый бюджет — робот все равно посещает страницу.
Долгое удаление из индекса «мусорных» страниц и дублей — исключение страниц может затянуться вплоть до 3-х месяцев, в зависимости от объема загруженных ранее документов.
Ключевое отличие: meta-тег robots работает на уровне индексации, а не сканирования. Он не запрещает роботу заходить на страницу, но точно указывает, что с ней делать после загрузки. Это инструмент точечного контроля и он незаменимый когда есть потребность управлять видимостью отдельных страниц без ограничения доступа к ним.
Типичная ошибка, которая стоит трафика
Самая распространенная ошибка — сочетание закрытия страниц обоими способами. На практике и согласно инструкциям поисковых систем, их одновременное применение приводит к прямо противоположному результату.
Google прямо указывает в своей документации:
Яндекс придерживается такой же логики:
Конкретный пример: интернет-магазин решил скрыть от индексации страницы с архивными товарами. В robots.txt добавили:
User-agent: *
Disallow: /archive/
А на самих страницах архива прописали:
<meta name="robots" content="noindex">
Результат: через месяц трафик на основные категории упал на 30%, а в поиске появились дубли страниц.
Механизм конфликта: почему робот не видит noindex.
1. Робот следует цепочке действий:
Первым делом проверяет robots.txt.
Видит запрет на сканирование /archive/.
Не загружает содержимое страниц из этой папки.
Соответственно, не видит мета-тег noindex.
2. Что происходит дальше:
Страницы архива остаются доступными по прямым ссылкам.
Робот находит их через внешние ссылки, данные метрик, карту сайта.
Поскольку запрет в robots.txt не блокирует индексацию, а только сканирование.
Страницы могут попасть в индекс без вашего контента, только с URL и Title.
Как проверить наличие такой ошибки на сайте:
1. Аудит robots.txt
Найдите все директивы Disallow.
Проверьте, не указаны ли в них адреса страниц с ценным контентом.
2. Анализ в Google Search Console
Откройте раздел «Страницы» → «Исключено».
Проверьте вкладку «Проиндексировано, но не в sitemap».
Изучите страницы с статусом «Сканирование разрешено? Нет».
3. Практический чек-лист:
Если страница должна быть в поиске — уберите ее из robots.txt
Если страница НЕ должна быть в поиске — используйте ТОЛЬКО meta-тег robots с параметром noindex
Если страница техническая и не должна загружаться — используйте Disallow
Простое правило: запрещаете сканирование — не рассчитывайте на индексацию. Нужно скрыть страницу из поиска — дайте роботу возможность прочитать meta-тег.
Готовые решения для типичных задач
Чтобы избежать распространенных ошибок, используйте эту таблицу как практическое руководство для ежедневной работы. Здесь собраны типовые сценарии и оптимальные решения для них.
Что выбрать в конкретной ситуации
Ваша задача
Инструмент
Пример настройки
Важные нюансы
Закрыть служебные папки
robots.txt
Disallow: /admin/ Disallow: /cgi-bin/
Не защищает от прямого доступа, требует дополнительных мер безопасности
Убрать страницу из поиска
meta-тег robots
<meta name="robots" content="noindex">
Страница все равно грузится роботом, но гарантированно исключается из выдачи
Скрыть дубли страниц
robots.txt
Disallow: /?sort=* Disallow: /?filter=*
Эффективно экономит краулинговый бюджет, блокируя параметры сортировки. Убедиться, что нет прямых внутренних ссылок
Закрыть PDF-файл
robots.txt + доп. меры
Disallow: /price.pdf
Для полной защиты нужна авторизация или дополнительная настройка сервера
Страница «Спасибо за заявку»
meta-тег robots
noindex, follow
Сохраняет вес ссылок для SEO, но не индексируется в поиске
Страница с комментариями
meta-тег robots
index, nofollow
Индексируется, но ссылки в комментариях не передают вес
Архивные товары
meta-тег robots
noindex, nofollow
Полностью исключает страницы из поиска и не учитывает ссылки
Технические файлы
robots.txt
Disallow: /*.js$ Disallow: /*.css$
Запрещает сканирование JS/CSS файлов для экономии бюджета. Убедиться, что поисковики рендерят страницы корректно
Ключевые выводы:
Robots.txt — для управления сканированием и экономии ресурсов.
Meta-тег robots — для точечного контроля индексации конкретных страниц.
Никогда не используйте оба метода одновременно для одной задачи.
Всегда проверяйте результат в поисковой консоли после внесения изменений.
Эта шпаргалка поможет принимать верные решения без глубокого погружения в технические детали, сохраняя эффективность SEO-продвижения и разумное использование ресурсов.
Частые ошибки и как их избежать
Даже опытные специалисты допускают ошибки в настройках для поисковых роботов. Вот самые распространенные из них, которые могут серьезно навредить видимости сайта.
1. Критическая ошибка. Закрытие в robots.txt страниц, которые должны быть в поиске.
Суть проблемы: директива Disallow блокирует доступ к важным разделам, которые должны индексироваться.
Пример: Disallow: /catalog/ — когда вся основная продукция находится в этой папке.
Последствия: робот не сканирует страницы, не видит свежий контент, позиции сайта падают.
Решение: проверьте, чтобы в Disallow не было путей к основным категориям, статьям блога и ключевым страницам.
2. Опасное действие. Использование noindex для главной страницы.
Суть проблемы: случайное или намеренное добавление noindex на главную страницу сайта.
Последствия: главная страница исчезает из поиска, что приводит к катастрофической потере трафика.
Решение: регулярно проверять заголовок главной страницы через сервисы проверки мета-тегов или в кодe.
3. Стратегическая ошибка. Закрытие целых разделов через meta-теги
Суть проблемы: массовое проставление noindex на сотнях или тысячах страниц (например, на всех архивных товарах) через meta-тег.
Последствия: робот вынужден тратить драгоценный краулинговый бюджет на загрузку каждой страницы, только чтобы увидеть директиву noindex и уйти. Это замедляет индексацию нового и важного контента.
Решение: для закрытия целых разделов от индексации используйте комбинацию методов:
Используйте заголовок X-Robots-Tag: noindex в HTTP-ответ для URL-шаблонов всего раздела через настройки сервера (.htaccess, nginx.conf). Это позволит роботу увидеть запрет еще до загрузки HTML-кода.
Используйте robots.txt для запрета сканирования технических и мусорных разделов, которые точно не должны быть в индексе (например, дубли страниц с параметрами фильтров).
Meta-тег robots оставьте для точечного управления небольшим количеством страниц.
4. Распространенная оплошность. Неправильные символы в директивах.
Суть проблемы: отсутствие слеша в начале пути, опечатки, неправильное использование спецсимволов.
Disallow: /page* (неправильно) → Disallow: /page (правильно для запрета всех URL, начинающихся с /page)
Последствия: директива не работает или работает некорректно.
Решение: использовать валидаторы robots.txt (например, в Яндекс Вебмастере или Google Search Console).
4. Техническая ловушка. Конфликт настроек разных систем (CMS, плагины)
Суть проблемы: настройки в CMS, SEO-плагинах (например, Yoast, RankMath) могут дублироваться или конфликтовать с прямыми правками в коде или robots.txt.
Пример: в robots.txt стоит Allow: /catalog/, а SEO-плагин массово проставил noindex на все страницы каталога.
Последствия: невозможно предсказать, какая из инструкций будет иметь приоритет.
Решение: выбрать один основной способ настройки (рекомендуется через SEO-плагин) и не дублировать его в других местах.
Чек-лист: 6 пунктов для быстрой проверки настроек
Потратьте 10 минут, чтобы проверить ваш сайт по этому списку и избежать серьезных проблем.
1. ✅ Проверьте главную страницу на наличие noindex.
Откройте исходный код страницы (Ctrl+U) и найдите meta name="robots". Убедитесь, что для главной нет значений noindex или none.
2. ✅ Проверьте robots.txt на наличие запретов для ключевых разделов.
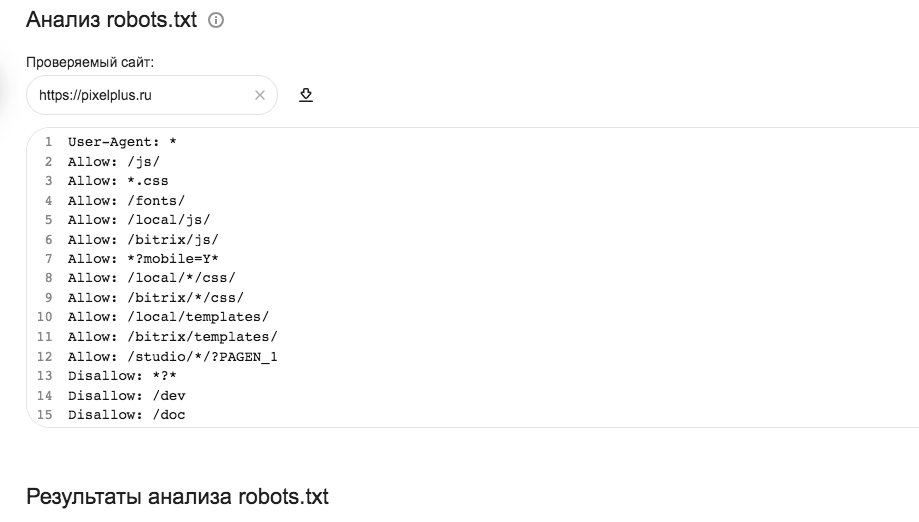
Самый простой способ проверить корректность файла robots.txt можно инструментом Яндекса: Анализ robots.txt — достаточно указать адрес главной страницы, система сама подгрузит содержимое файла:
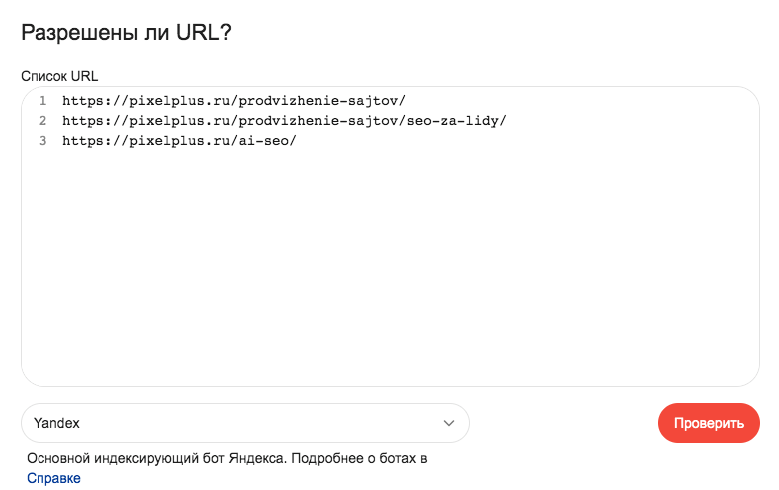
Останется только ввести URL продвигаемых страниц:
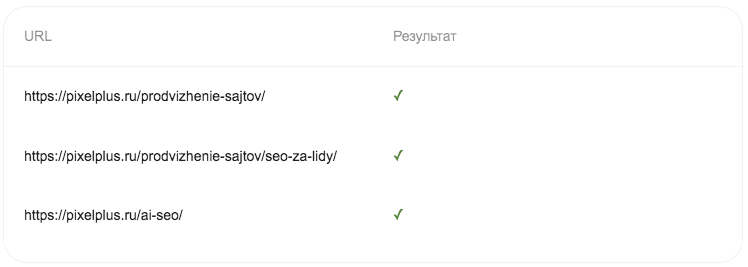
И убедиться, что доступ к ним согласно текущей версии сайта, открыт (при условии, что правила общие для всех поисковиков):
3. ✅ Убедитесь, что для страниц, закрытых в robots.txt, не назначен noindex.
Выберите несколько страниц из Disallow-списка и проверьте через инструменты вебмастеров, не проиндексированы ли они. Если да — это ошибка.
4. ✅ Проверьте синтаксис robots.txt на валидность.
воспользуйтесь инструментами валидации в Яндекс Вебмастере или Google Search Console. Устраните найденные ошибки.
5. ✅ Проверьте наличие конфликтующих инструкций из CMS и плагинов.
Откройте настройки вашего SEO-плагина и найдите раздел, отвечающий за индексацию. Сравните эти настройки с тем, что прописано вручную в коде шаблона.
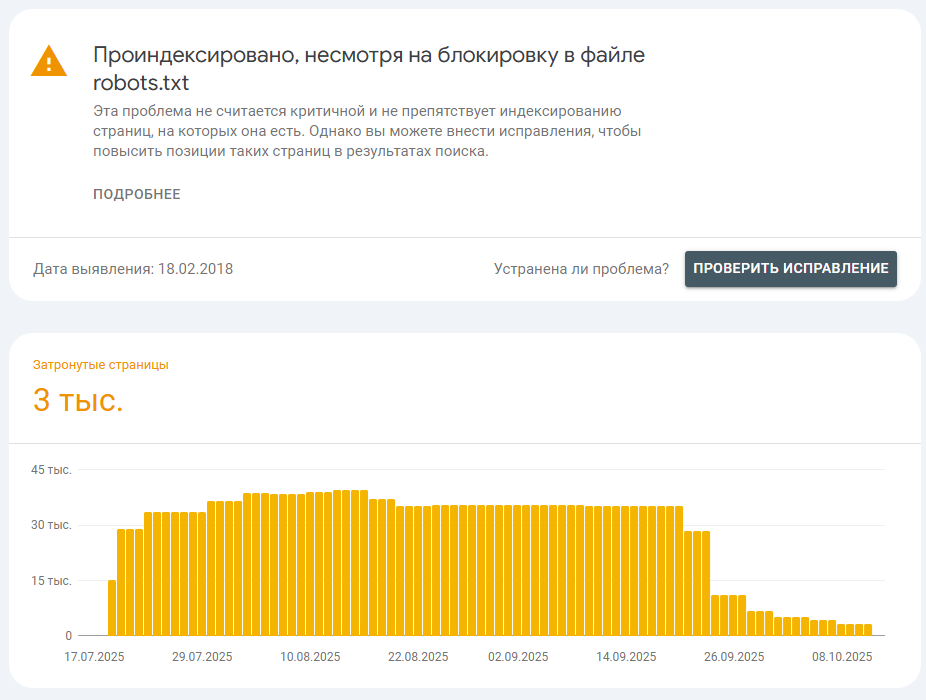
6. ✅ Проверьте наличие страниц в индексе поисковой системы Google, несмотря на закрытие их в файле robots.txt.
Узнать, есть ли сейчас проблема с нахождением страниц в индексе можно в панели Google Search Console, достаточно перейти в раздел «Страницы» и открыть список страниц со статусом «Проиндексировано, несмотря на блокировку в файле robots.txt».
Регулярное выполнение этого чек-листа — лучшая страховка от технических ошибок, которые могут подорвать SEO-усилия.
Главные правила, которые нужно запомнить
После детального разбора двух инструментов становится очевидной простая, но эффективная стратегия их использования. Запомните эти три правила — они избавят вас от 95% возможных ошибок.
Файл robots.txt — для управления сканированием. Meta-тег robots — для управления индексацией. Это — фундаментальное различие. Первый инструмент решает, куда робот может зайти, второй — что ему делать с контентом, когда он уже внутри. Смешивать их назначение — все равно, что пытаться закрыть дверь на ключ с обеих сторон.
Никогда не закрывайте в robots.txt то, что должно быть noindex. Это самая дорогостоящая ошибка. Если вы хотите убрать страницу из поиска, робот обязан иметь возможность загрузить ее и прочитать ваш запрет. Запрещая доступ в robots.txt, вы прячете от робота саму инструкцию noindex, и страница может быть проиндексирована.
Любые изменения сразу проверяйте на корректность. Не полагайтесь на удачу. Такие инструменты, как Яндекс Вебмастер и Google Search Console, покажут, как именно поисковые системы видят ваш сайт. Проверяйте статус сканирования и индексации ключевых страниц до и после внесения правок.
Потратьте 10 минут прямо сейчас на проверку текущих настроек вашего проекта по нашему чек-листу — эти простые действия уберегут ваш бизнес от неожиданных потерь трафика и дохода в будущем!
Ну наконец-то кто-то написал по делу и без воды. Интересно, конечно, если бы раскрыли тему и по X-Robots-Tag, но, я так понимаю, его используют единицы... Как показывает практика, 99,9% решают проблему через robots.txt, при чем даже не задумываясь, что тот же Гугл может проигнорировать этот запрет))
Спасибо, Ваш комментарий отправлен.
Ответить
a:1:{i:0;s:3:"239";}
Наши достижения
Входим в число лучших компаний России в сферах интернет-рекламы и разработки сайтов по результатам самых авторитетных рейтингов
Победитель в номинации «SEO для e-commerce» по итогам
WORKSPACE DIGITAL AWARDS 2025
Победитель в номинации «SEO под ключ» по итогам
WORKSPACE DIGITAL AWARDS 2024
Рейтинг с самой прозрачной методологией
SEO глазами клиентов 2023
Рейтинг известности SEO-компаний 2020 по версии
SEO-news
Боты, каналы, группы в МАКС: в...
На фоне нестабильной работы зарубежных сервисов МАКС перестал быть «запасным аэродромом» и превратился в полноценную экосистему для бизнеса
28 июня
Создание канала или группы в М...
Блокировка WhatsApp и Telegram побудили бизнес искать альтернативные пути для контакта с клиентами, партнерами и внутренними командами.
28 июня
GEO-продвижение: гайд повышени...
GEO (Generative Engine Optimization) — это направление онлайн-маркетинга, направленное на рост видимости и числа упоминаний бренда и его...
Как стать № 1 в Google за счет...
Одна из проблем, которая существенно тормозит продвижение сайта в результатах выдачи Яндекс и Google, неверное понимание зон ответственности сторон &m...
5 способов, как посмотреть сай...
Если робот Googlebot не может получить доступ к контенту страницы, он не может быть процитирован, а значит страница не займет ожидаемые позиции и не п...
20 августа
Реклама в мобильных приложениях
По информации маркетингового агентства Crucial, пользователи смартфонов проводят в приложениях около 88% мобильного времени.
Сколько стоит разработка прило...
Бюджет на разработку приложения такси, скрытые затраты и больные вопросы маркетинга для быстрого запуска и окупаемости.
28 июня
Боты, каналы, группы в МАКС: в...
На фоне нестабильной работы зарубежных сервисов МАКС перестал быть «запасным аэродромом» и превратился в полноценную экосистему для бизнеса
28 июня
Создание канала или группы в М...
Блокировка WhatsApp и Telegram побудили бизнес искать альтернативные пути для контакта с клиентами, партнерами и внутренними командами.
Разработка мобильных приложени...
Разработка мобильного приложения как бизнес-стратегия. Как создать приложение, которое станет каналом продаж с понятным ROI.
IoT разработка: как создать ре...
IoT разработка — это создание систем, в которых физические устройства собирают данные и обмениваются ими через интернет. В этой статье разобрано всё: ...
В этой статье объясняется, что такое API, как устроен принцип его работы и где он применяется. Материал будет полезен разработчикам, предпринимател...
10 апреля
UX-исследования: методы, виды ...
Создание цифровых продуктов сегодня — это сложный процесс, где каждая ошибка может стоить миллионы. Чтобы не действовать вслепую и не тратить бю...
Принципиально новые условия сотрудничества в SEO — зарабатываем только вместе!
Уникальный тариф «Оборот», где доход агентства больше не зависит от визитов и позиций вашего сайта, а привязан исключительно к росту оборота вашей компании.
Максимальное погружение агентства в нюансы вашего бизнеса, конкурентного окружения и тематики.
Самый прозрачный показатель эффективности, который нельзя «накрутить».
Идеально подходит для интернет-магазинов и сайтов услуг с возможностью масштабирования.
Минимальная фиксированная часть оплаты — от 79 500 рублей.
Тариф, который хотели сделать многие, но реализовали только мы.